I spend my daytime hours as a system administrator at a research institute in a heterogeneous computing environment. We have two big compute clusters (one on CentOS the other on Ubuntu) with about 100 nodes each and dozens of custom GNU/Linux workstations. A common task for me is to ensure the users can run their bioinformatics software, both on their workstation and on the clusters. Only few bioinformatics tools and libraries are popular enough to have been packaged for CentOS or Ubuntu, so usually some work has to be done to build the applications and all of their dependencies for the target platforms.
In theory, compiling software is not a very difficult thing to do. Once all development headers have been installed on the build host, compilation is usually a matter of configuring the build with a configure script and running GNU make with various flags (this is an assumption which is violated by bioinformatics software on a regular basis, but let’s not get into this now). However, there are practical problems that become painfully obvious in a shared environment with a large number of users.
Compiling software directly on the target machine is an option only in the most trivial cases. With more complicated build systems or complicated build-time dependencies there is a strong incentive for system administrators to do the hard work of setting up a suitable build environment for a particular piece of software only once. Most people would agree that package management is a great step up from naive compilation, as the build steps are formalised in some sort of recipe that can be executed by build tools in a reproducible manner. Updates to software only require tweaks to these recipes. Package management is a good thing.
Non-trivial software that was built and dynamically linked on one machine with a particular set of libraries and header files at particular versions can only really work on a system with the very same libraries at compatible versions in place. Established package managers allow packagers to specify hard dependencies and version ranges, but the binaries that are produced on the build host will only work under the constraints imposed on them at build time. To support an environment in which software must run on, say, both CentOS 6.5 and CentOS 7.1, the packages must be built in both environments and binaries for both targets have to be provided.
There are ways to emulate a different build environment
(e.g. Fedora’s mockbuild), but we cannot get around the
fact that dynamically linked software built for one kind of
system will only ever work on that very kind of system. At
runtime we can change what libraries will be dynamically loaded,
but this is a hack that pushes the problem from package
maintainers to users. Running software with LD_LIBRARY_PATH set is not a solution, nor is static linking,
the equivalent to copying chunks of libraries at build time.
Libraries and applications that come pre-installed or pre-packaged with the system may not be the versions a user claims to need. Say, a user wants the latest version of GCC to compile code using new language features specified in C++11 (e.g. anonymous functions). Full support for C++11 arrived in GCC 4.8.1, yet on CentOS 6.5 only version 4.4.7 is available through the repositories. The system administrator may not necessarily be able to upgrade GCC system-wide. Or maybe other users on a shared system do need version 4.4.7 to be available (e.g. for bug-compatibility). There is no easy way to satisfy all users, so a system administrator might give up and let users build their own software in their home directories instead of solving the problem.
However, compiling GCC is a daunting task for a user and they
really shouldn’t have to do this at all. We already established
that package management is a good thing; why should we deny users
the benefits of package management? Traditional package
management techniques are ill-suited to the task of installing
multiple versions of applications or libraries into independent
prefixes. RPM, for example, allows users to maintain a local,
independent package database, but yum won’t work with
multiple package databases. Additionally, only one
package database can be used at once, so a user would have to
re-install system libraries into the local package database to
satisfy dependencies. As a result, users lose the important
feature of automatic dependency resolution.
A system administrator who decides to package software as relocatable RPMs, to install the applications to custom prefixes and to maintain a separate repository has nothing to show for when a user asks to have the packaged software installed on an Ubuntu workstation. There are ways to convert RPMs to DEB packages (with varying degrees of success), but it seems silly to have to convert or rebuild stuff repeatedly when the software, its dependencies and its mode of deployment really didn’t change at all.
What happens when a Slackware user comes along next? Or someone using Arch Linux? Sure, as a system administrator you could refuse to support any system other than CentOS 7.1, users be damned. Traditionally, it seems that system administrators default to this style for convenience and/or practical reasons, but I consider this unhelpful and even somewhat oppressive.
Luckily, I’m not the only person to consider traditional packaging methods inadequate for a number of valid purposes. There are different projects aiming to improve and simplify software deployment and management, one of which I will focus on in this article. As a functional programmer, Scheme aficionado and free software enthusiast I was intrigued to learn about GNU Guix, a functional package manager written in Guile Scheme, the designated extension language for the GNU system.
In purely functional programming languages a function will produce the very same output when called repeatedly with the same input values. This allows for interesting optimisation, but most importantly it makes it possible and in some cases even easy to reason about the behaviour of a function. It is independent from global state, has no side effects, and its outputs can be cached as they are certain not to change as long as the inputs stay the same.
Functional package management lifts this concept to the realm of
software building and deployment. Global state in a system
equates to system-wide installations of software, libraries and
development headers. Side effects are changes to the global
environment or global system paths such as /usr/bin/.
To reject global state means to reject the common file system
hierarchy for software deployment and to use a minimal chroot for building software. The introduction of the Guix
manual describes the approach as follows:
The term “functional” refers to a specific package management discipline. In Guix, the package build and installation process is seen as a function, in the mathematical sense. That function takes inputs, such as build scripts, a compiler, and libraries, and returns an installed package. As a pure function, its result depends solely on its inputs—for instance, it cannot refer to software or scripts that were not explicitly passed as inputs. A build function always produces the same result when passed a given set of inputs. It cannot alter the system’s environment in any way; for instance, it cannot create, modify, or delete files outside of its build and installation directories. This is achieved by running build processes in isolated environments (or “containers”), where only their explicit inputs are visible.
The result of package build functions is “cached” in the file system, in a special directory called “the store”. Each package is installed in a directory of its own, in the store—by default under ‘/gnu/store’. The directory name contains a hash of all the inputs used to build that package; thus, changing an input yields a different directory name.
The following diagram (taken from the slides for a talk by Ludovic Courtès) illustrates how the build daemon handles the package build processes requested by a client via remote procedure calls:
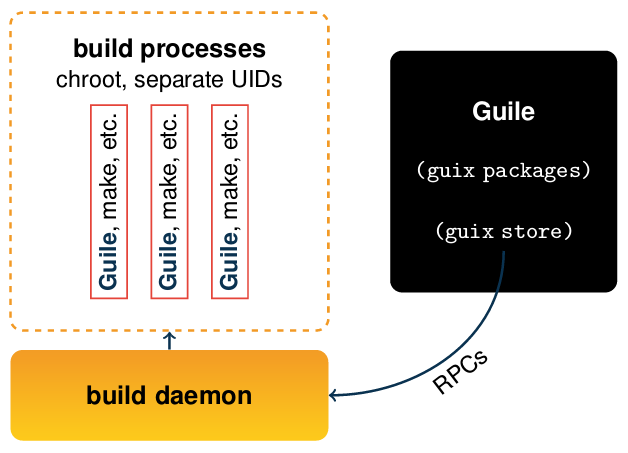
Note that the package outputs are still dynamically linked. Libraries are referenced in the binaries with their full store paths using the runpath feature. These package outputs are no self-contained, monolithic application directories as you might know them from MacOS.
Any built software is cached in the store which is shared by all
users system-wide. However, by default the software in the store
has no effect whatsoever on the users’ environments. Building
software and have the results stored in /gnu/store does
not alter any global state; no files pollute /usr/bin/
or /usr/lib/. Any effects are restricted to the
package’s single output directory inside the /gnu/store.
Guix provides per-user profiles to map software from the store into a user environment. The store provides deduplication as it serves as a cache for packages that have already been built. A profile is little more than a “forest” of symbolic links to items in the store. The union of links to the outputs of all software packages the user requested makes up the user’s profile. By adding another layer of symbolic link indirection, Guix allows users to seamlessly switch among different generations of the same profile, going back in time.
Each user profile is completely isolated from one another, making it possible for different users to have different versions of GCC installed. Even one and the same user could have multiple profiles with different versions of GCC and switch between them as needed.
Guix takes the functional packaging method seriously, so except for the running kernel and the exposed machine hardware there are virtually no dependencies on global state (i.e. system libraries or headers). This also means that the Guix store is populated with the complete dependency tree, down to the kernel headers and the C library. As a result, software in the Guix store can run on very different GNU/Linux distributions; a shared Guix store allows me to use the very same software on my Fedora workstation, as well as on the Ubuntu cluster, and on the CentOS 6.5 cluster.
This means that software only has to be packaged up once. Since package recipes are written in a very declarative domain-specific language on top of Scheme, packaging is surprisingly simple (and to this Schemer is rather enjoyable).
Guix liberates users from the software deployment decisions of their system administrators by giving them the power to build software into an isolated directory in the store using simple package recipes. Administrators only need to configure and run the Guix daemon, the core piece running as root. The daemon listens to requests issued by the Guix command line tool, which can be run by users without root permissions. The command line tool allows users to manage their profiles, switch generations, build and install software through the Guix daemon. The daemon takes care of the store, of evaluating the build expressions and “caching” build results, and it updates the forest of symbolic links to update profile state.
Users are finally free to conveniently manage their own software, something they could previously only do in a crude manner by compiling manually.
Guix is not designed to be run in a centralised manner. A Guix daemon is supposed to run on each system as root and it listens to RPCs from local users only. In an environment with multiple clusters and multiple workstations this approach requires considerable effort to make it work correctly and securely.

Instead we opted to run the Guix daemon on a single dedicated server, writing profile data and store items onto an NFS share. The cluster nodes and workstations mount this share read-only. Although this means that users lose the ability to manage their profiles directly on their workstations and on the cluster nodes (because they have no local installation of the Guix client or the Guix daemon, and because they lack write access to the shared store), their software profiles are now available wherever they are. To manage their profiles, users would log on to the Guix server where they can install software into their profiles, roll back to previous versions or send other queries to the Guix daemon. (At some point I think it would make sense to enhance Guix such that RPCs can be made over SSH, so that explicit logging on to a management machine is no longer necessary.)
Since winter 2014 I have been packaging software for GNU Guix, which meanwhile has accumulated quite a few common and obscure bioinformatics tools and libraries. A list of software (updated daily) available through Guix is available here. We also have common Python modules for scientific computing, as well as programming languages such as R and Julia.
I think GNU Guix is a great platform for scientific software in
heterogeneous computing environments. The Guix project follows
the Free System Distribution Guidelines, which mean that free
software is welcome upstream. For software that imposes
additional usage or distribution restrictions (such as when the
original Artistic license is used instead of the Clarified
Artistic license, or when commercial use is prohibited by the
license) Guix allows the use of out-of-tree package modules
through the GUIX_PACKAGE_PATH variable. As Guix
packages are just Scheme variables in Scheme modules, it is
trivial to extend the official GNU Guix distribution with package
modules by simply setting the GUIX_PACKAGE_PATH.
If you want to learn more about GNU Guix I recommend taking a look at the excellent GNU Guix project page. Feel free to contact me if you want to learn more about packaging scientific software for Guix. It is not difficult and we all can benefit from joining efforts in adopting this usable, dependable, hackable, and liberating platform for scientific computing with free software.
The Guix community is very friendly, supportive, responsive and welcoming. I encourage you to visit the project’s IRC channel #guix on Freenode, where I go by the handle “rekado”.
Comments? Then send me an email! Interesting comments may be published here.